12 Testing
12.1 It's t-time
In the last chapter we used linear models to calculate estimates, estimates of mean difference and confidence intervals. As we can set our confidence intervals to whatever threshold we choose - reporting these without P should be sufficient for any estimation we choose. It's the interesting bit, reporting the direction and effect size of any relationship or difference at whatever confidence threshold we want.
P-values by comparison, are boring, no-one actually cares about P-values, but you would be forgiven for thinking they are the most important thing about statistics from the way we often see them presented. And so, inevitably, you will be asked to supply a P-value for many of your lab reports, dissertations (and maybe future scientific papers). Luckily significance tests come parcelled in with the coefficients of our linear models.
12.2 Student's t-test
The Student's t-test uses the t-distribution, a small-sample size version of the normal distribution, where tails are fatter if the degrees of freedome are small. There are two basic types of t-test which we have encountered with our linear models.
- The one sample t-test: takes the mean of a sample and compares it with the null hypothesis of zero
lm(y ~ 1)
lm (height~1)- The two sample t-test which compares the difference between the means of two samples against a null hypothesis of no difference between the means of the two populations.
The general equation for calculating t is:
\[ t = \frac{difference}{SE} \]
SO the calculation of the t-value is essentially counting the standard errors, our rough rule of thumb is that the estimate of the difference is about twice as large as the standard error at a confidence interval of 95%, and about three times as large as the standard error at a confidence interval of 99%.
This is very approximate and becomes less robust at smaller sample sizes, because when sample sizes are large the t-distribution is roughly equal to a normal (z) distribution. However, when sample sizes are small the t-distribution has a shorter and wider distribution (we need larger standard errors to capture our 95% confidence interval).
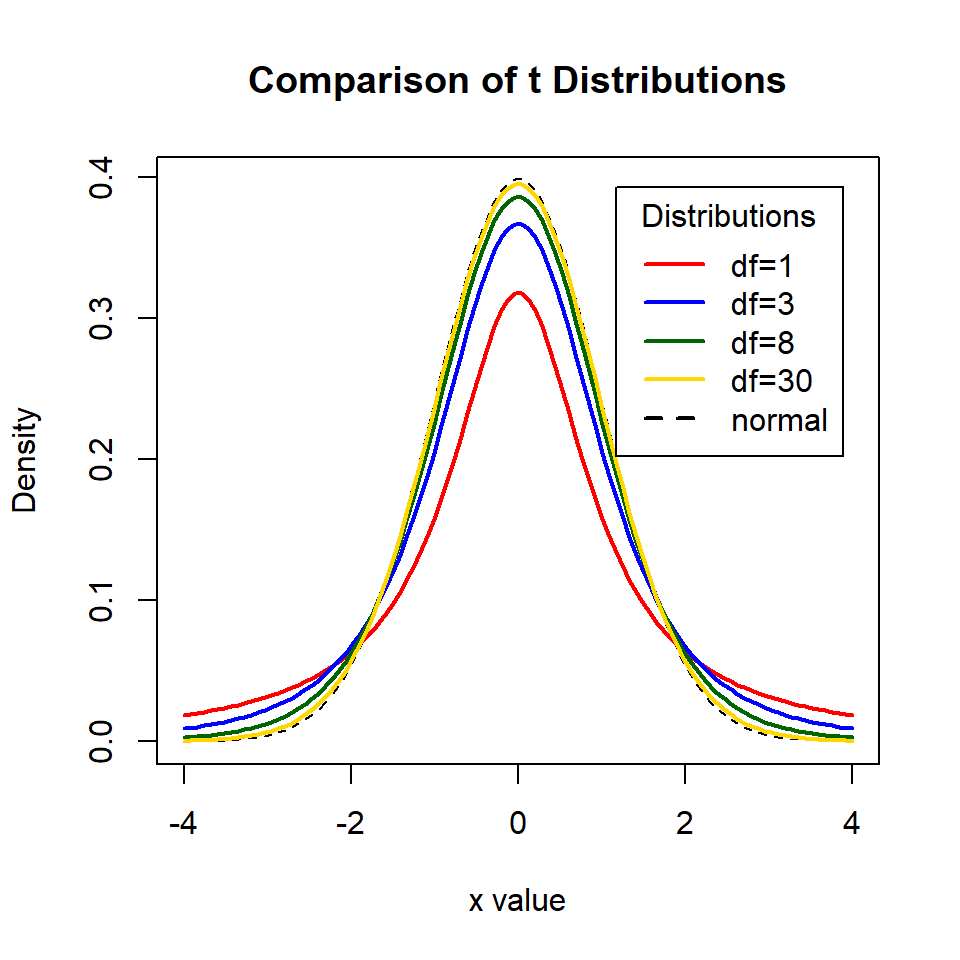
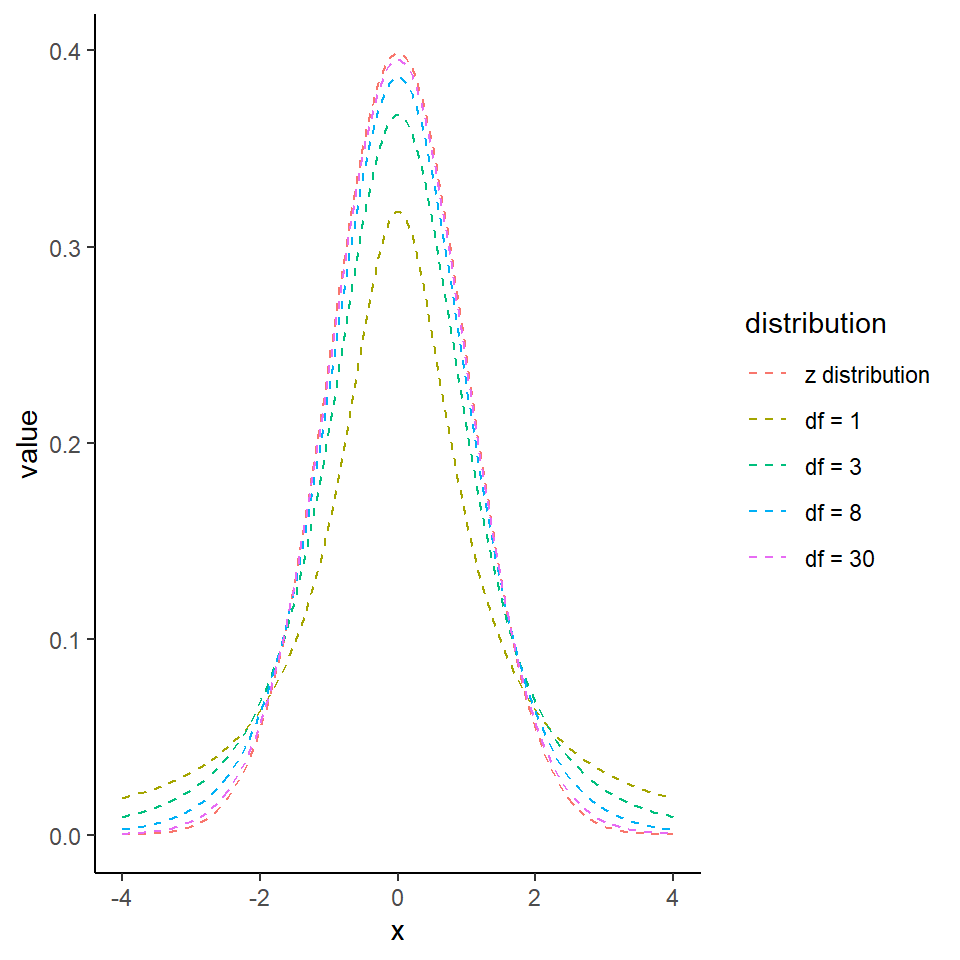
A potential source of confusion when discussing t is that there are two values that must be considered. There is critical t the value which must be exceeded for the test to be significant (e.g. generates a P value that is less than our predefined \(\alpha\)). The critical value for t is defined by the df. Then there is the observed value of t, this is the value returned by your statistical test, calculated by \(\frac{difference}{SE}\). When \(observed~t > critical~t\) the result can be declared significantly different at that threshold for \(\alpha\).
We are spending a lot of time with t because it is the default value generated by our linear model outputs, instead of assuming a normal distriubtion and using z. Recall that for a z distribution the critical value for P = 0.05 is \(1.96 * SE\) (or roughly double the Standard Error), and actually if we look at the figure above, we can see that even at only 8 df the distribution of t is starting to look pretty close to a z distribution. The values for critical t at each degree of freedom up to 30 are presented below
df <- c(1:30)
# map_dbl forces returned values to be a single vector of numbers (rather than a list)
critical_t <- map_dbl(df, ~qt(p=0.05/2, df=.x, lower.tail=FALSE))
tibble(df,critical_t) %>%
ggplot(aes(x=df, y=critical_t))+
geom_point()+
geom_line()+
geom_hline(aes(yintercept=1.96), linetype="dashed", colour="red")+
labs(x= "Degrees of Freedom",
y= expression(paste("Critical value of ", italic("t"))))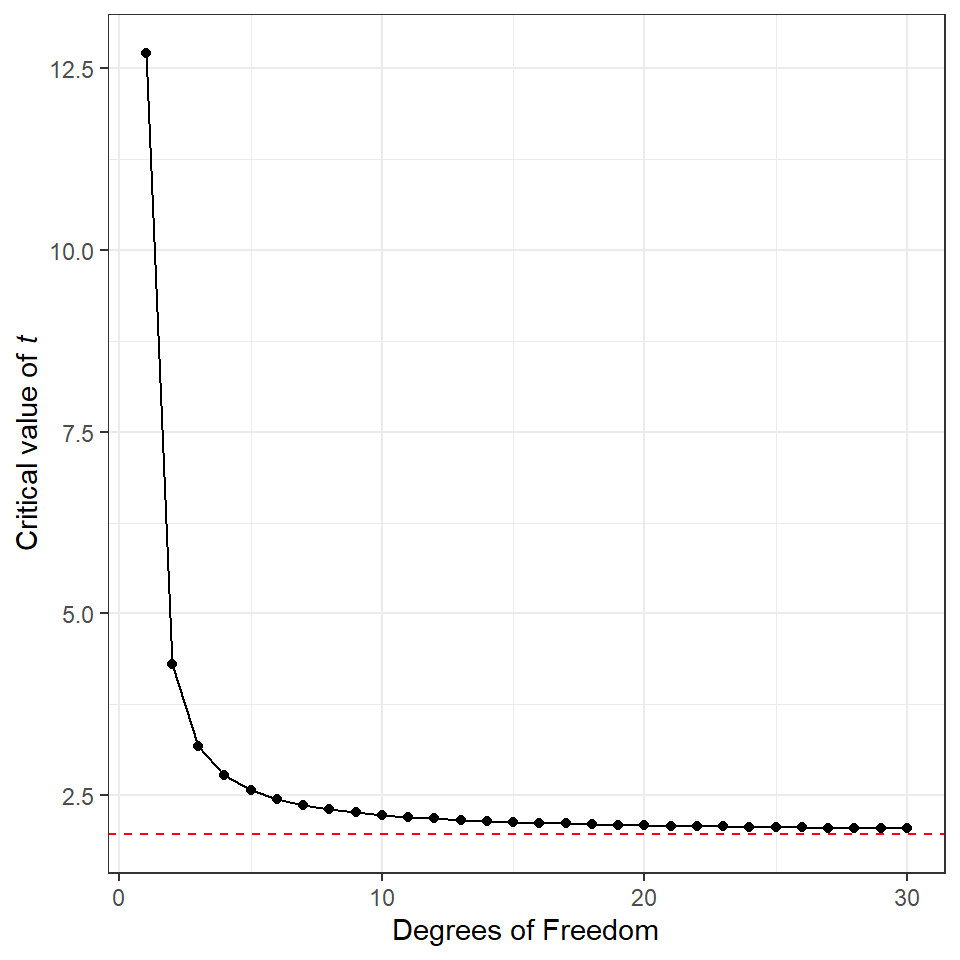
So far we have used a mixture of the base R summary() function and the broom package tibbles produced by broom::tidy(). Summary is the most common way to investigate a model result, but it is its own specific type of R object (e.g. not a dataframe or a tibble), which is why tidying the results into a dataframe like structure can be useful.
Using either method we can can see that they include t-tests for the coefficient, summary explicity calls them t, while tidy() refers to them generically as the 'statistic'
lsmodel1 <- lm(height ~ type, data = darwin)The linear model summary will automatically apply a test to every row of our table, sometimes these are the important apriori tests defined by our hypothesis, and sometimes they are not.
As an example the second row of our table is a test we planned to perform, it tests our null hypothesis by comparing the average observed difference in plant heights between cross and self-pollinated plants, it calculates the average difference (estimate), the amount of uncertainty (std. error), then calculates an observed t value and determines the probability of observing an effect of at least this size (at this sample size) if the null hypothesis is true.
However, the first row also performs a t-test, it tests a null hypothesis that the intercept (here the mean height of the cross-pollinated plants) is zero. This was not a comparison we intended to make, nor is it likely that this test is particularly useful.
Anyway the observed difference in plant heights was 2.62 inches ± 1.07, which produces an observed value of t as:
tidy_model1 <- broom::tidy(lsmodel1)
tidy_model1[[2,2]] / tidy_model1[[2,3]]## [1] -2.437113Which could be the same as the value for t in our model summary.
12.3 Paired t
The structure of our linear model so far has produced the output for a standard two-sample Student's t-test. However, when we first calculated our estimates by hand - we started by making an average of the paired differences in height. To generate the equivalent of a paired t-test, we simply have to add the factor for pairs to our linear model formula:
The table of coefficients suddenly looks a lot more complicated! This is because now the intercept is the height of the crossed plant from pair 1:
The second row now compares the mean heights of Crossed and Selfed plants when they are in the same pair
rows three to 16 compare the average difference of each pair (Crossed and Selfed combined) against pair 1
Again the linear model computes every possible combination of t-statistic and P-value, however the only one we care about is the difference in Cross and Self-pollinated plant heights. If we ignore the pair comparisons the second row gives us a paired t-test. 'What is the difference in height between Cross and Self-pollinated plants when we hold pairs constant.'
For completeness let's generate the confidence intervals for the paired t-test.
lm(height ~ type + factor(pair), data = darwin) %>%
broom::tidy(., conf.int=T) %>%
slice(1:2) # just show first two rows| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 21.745833 | 2.436389 | 8.925435 | 0.0000004 | 16.520298 | 26.9713683 |
| typeSelf | -2.616667 | 1.218195 | -2.147988 | 0.0497029 | -5.229434 | -0.0038992 |
We can see that estimate of the mean difference is identical but the 95% confidence intervals are now slightly different. So in this particular version we have actually increased our level of uncertainty by including the pair parameter.
m1 <- lm(height ~ type, data = darwin) %>%
broom::tidy(., conf.int=T) %>%
slice(2:2) %>%
mutate(model="unpaired")
m2 <- lm(height ~ type + factor(pair), data = darwin) %>%
broom::tidy(., conf.int=T) %>%
slice(2:2) %>%
mutate(model="paired")
rbind(m1,m2) %>%
ggplot(aes(model, estimate))+
geom_pointrange(aes(ymin=conf.high, ymax=conf.low))+
geom_hline(aes(yintercept=0), linetype="dashed")+
theme_minimal()+
coord_flip()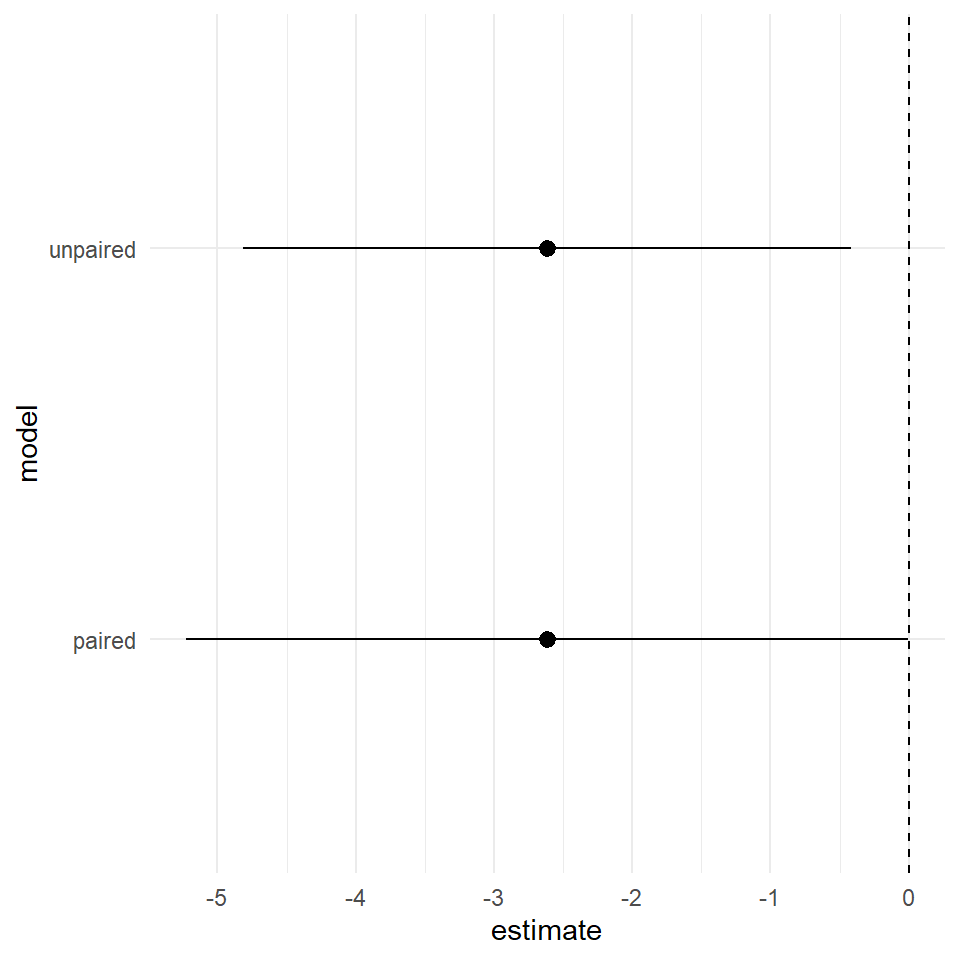
Choosing the right model
In future sessions we will work through model building and simplification, in this case we had a good a priori reason to include pair in our initial model, there are then simple tests we can do to see if it is safe to remove it, if it doesn't appear to be adding to our explanation of the difference in heights between self and cross-fertilised plants.
12.4 Effect sizes
We have discussed the importance of using confidence intervals to talk about effect sizes. When our 95% confidence intervals do not overlap the intercept, this indicates we have difference in our means which is significant at \(\alpha\) = 0.05. More interestingly than this it allows us to talk about the 'amount of difference' between our treatments, the lower margin of our confidence intervals is the smallest/minimum effect size. On the response scale of our variables this is very useful, we can report for example that there is at least a 0.43 inch height difference between self and crossed fertilised plants at \(\alpha\) = 0.05.
12.5 Type 1 and Type 2 errors
The repeatability of results is a key part of the scientific method. Unfortunately there is often an emphasis in the literature on 'novel findings', which means that unusual/interesting results that happen to reach statistical significance may be more likely to be published. The reality is that we know if we set an \(\alpha\) = 0.05, that we run the risk of rejecting the null hypothesis incorrectly in 1 in 20 of our experiments (A Type 1 error).
Type 2 errors. Statistical tests provide you with the probability of making a Type 1 error (rejecting the null hypothesis incorrectly) in the form of P. But what about Type 2 errors? Keeping the null hypothesis, when we should be rejecting it? Or not finding an effect.
The probability of making a Type 2 error is known as \(1-\beta\), where \(\beta\) refers to your statistical 'power'. Working out statistical power is is very straightforward for simple tests, and then becomes rapidly more diffcult as the complexity of your analysis increases... but it is an important concept to understand.
On the other side of the coin is experimental power - this is strength of your experiment to detect a statistical effect when there is one. Power is expressed as 1-\(\beta\). You want beta error typically to be less than 20%. So, you want a power of about 80%. That is you have an 80% chance of finding an effect if it's there.
All experiments/statistical analyses will become statistically significant if you make the sample size large enough. In this respect it shows how misleading a significant result can be. It is not that interesting if a result is statistically significant, but the effect size is tiny.
12.6 Repeatability
It is not possible for you to know from a single experiment whether you have made Type 1 or Type 2 errors. However, over time as experiments are eventually repeated the literature builds up allowing us to synthesise the evidence. Let's try that now & imagine a scenario where Darwin's experiment has been repeated another 20 times.
In the example below we have made a for loop that assumes we 'know' the true mean difference of crossed and fertilised plants and the standard deviation of the 'population'(we have taken Darwin's experimental data for this). The for loop then creates 20 new sampling experiments, and calculates the estimated mean difference for each experiment
set.seed(1234)
myList <- vector("list", 20)
y <- tibble()
for (i in 1:length(myList)) {
x <- rnorm(n=12, mean=2.6, sd=2.83)
data <- tibble(x)
temp <- lm(x~1, data=data) %>%
broom::tidy(conf.int=T)
y <- rbind(y,temp)
}
y$`experiment number` <- rep(1:20)
# the new dataframe y contains the results of 20 new experiments12.7 Activity 1: Experimental Repeatability
In my example nearly a third of the experiments did not find a statistically significant difference. A less formal review of the research might tally these P-values and conclude that there are inconsistent results in the literature.
A better way would be to look at the estimates and calculated confidence intervals
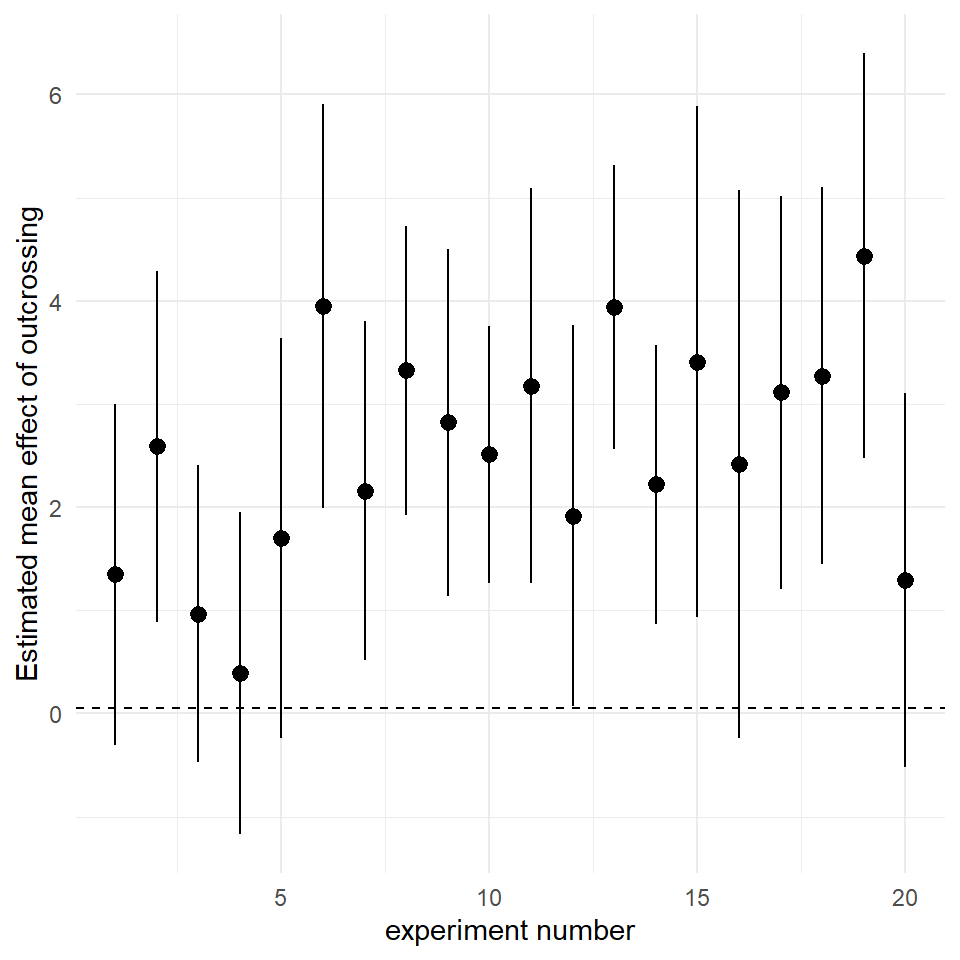
By illustrating this visually, it is clearer to see that the results are not really inconsistent, the negative effects of inbreeding depression are clear to see in all of the experiments - we are simply observing the effect of sampling error.
All 20 studies showed the effect of inbreeding depression, and all the experiments have identical levels of uncertainty. We can clearly see that estimates and intervals are a substantial improvement in the way we report experiments, and that they make comparisons across repeated studies more valuable.
12.8 Summary
This chapter finally allowed us to calculate P-values and test statistical significance for our experiments using linear models. We also compared the linear model structures for producing a paired vs. unpaired t-test.
However we also learned to appreciate the potential issues around making Type 1 and Type 2 errors, and how an appreciation of confidence intervals and standardised effect sizes can be used to assess these.
A single experiment is never definitive, and a reliance on reporting P-values is uninformative and can be misleading. Instead reporting estimates and confidence intervals allows us to report our levels of uncertainty, and provides results which are more informative for comparitive studies.