15 Multivariate linear models
So far we have worked almost exclusively with single explanatory variables either continuous (regression) or categorical (t-test or ANOVA). But what about analyses where we have more than one possible explanatory variable? Extra terms can easily be incorporated into linear models in order to test this.
15.1 Factorial linear models
The example data is the response of above ground plant biomass production of grassland plots in relation to two resource addition treatments. The addition of Fertiliser to the soil and the addition of Light to the grassland understorey. If biomass is limited by the nutrients in the soil, we would expect the addition of fertiliser to increase production. If biomass is limited by low levels of light caused by plant crowding we would expect an addition of light to increase biomass.
biomass <- read_csv(here::here("book", "files", "biomass.csv"))You should first check the data and look at the top rows, we can see that this shows the application or non-application of fertiliser and light additions, because all four possible combinations are present, this is known as a fully factorial design:
control (F- L-, no added light or fertiliser)
fertiliser (F+ L-)
light (F- L+)
addition of both (F+ L+)
Close inspection of the dataset shows that the same data is presented in two ways:
Column 1 shows the status of Fertiliser only (F +/-) (two levels)
Column 2 shows the status of Light only (L +/-) (two levels)
Column 3 shows whether fertiliser and light have been applied (four levels, a combination of the previous two columns)
Column 4 shows the biomass
15.2 Data summary
So we have 64 observations with four variables, the last column is the response variable (biomass) and the other three columns are two different ways of indicating the experimental design.
If we use column 3 - we are treating the design as though it is a one-way ANOVA (with four levels)
If we use columns 1 & 2 - we are treating this as a factorial design
We will look at the two different ways to analyse this data then, and the pros and cons of these two approaches.
15.3 One-way ANOVA
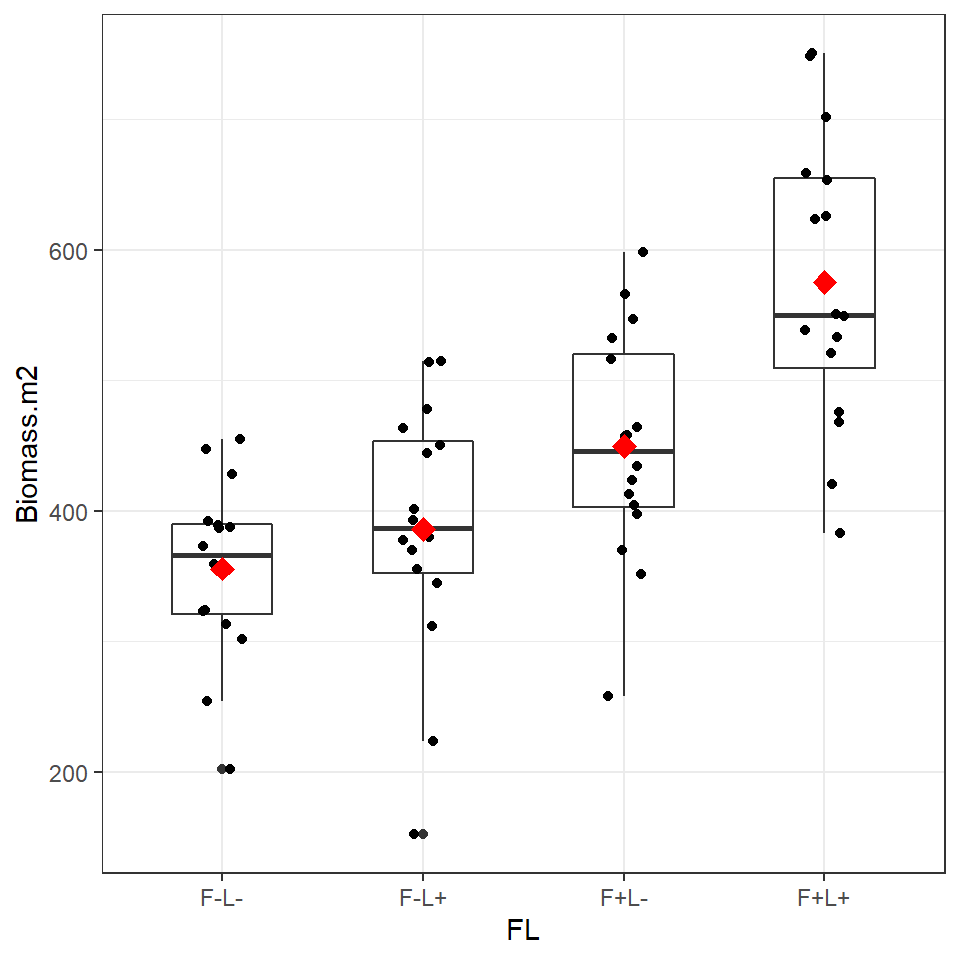
Figure 6.2: Boxplot and individual biomass values (black points) with treatment means (red diamonds)
Plotting the data and superimposing mean values produces the graph shown above. Now we are confident there is a difference in our sample means, we can begin a linear model to quantify this and test it against a null hypothesis.
If we use the FL column as a predictor then this is equivalent to a four-level one way ANOVA.
##
## Call:
## lm(formula = Biomass.m2 ~ FL, data = biomass)
##
## Residuals:
## Min 1Q Median 3Q Max
## -233.619 -42.842 1.356 67.961 175.381
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 355.79 23.14 15.376 < 2e-16 ***
## FLF-L+ 30.12 32.72 0.921 0.36095
## FLF+L- 93.69 32.72 2.863 0.00577 **
## FLF+L+ 219.23 32.72 6.699 8.13e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 92.56 on 60 degrees of freedom
## Multiple R-squared: 0.4686, Adjusted R-squared: 0.442
## F-statistic: 17.63 on 3 and 60 DF, p-value: 2.528e-08We can see that the control treatment (F- L-) is the intercept with a mean of 356g and standard error of 23g. The Light treatment adds an average of 30g to the biomass (but this close to the standard error of this estimated mean difference - 32.72g). In contrast the addition of fertiliser adds 93g to the biomass.
If we wanted to get the precise confidence intervals we could use broom::tidy(ls_1, conf.int = T) or confint(ls1).
We can visualise these differences with a coefficient plot, and see clearly that adding light by itself produce a slight increase in the mean biomass of our samples but the 95% confidence interval includes zero, so we don't have any real confidence that this is a consistent/true effect.
GGally::ggcoef_model(ls_1,
show_p_values=FALSE,
signif_stars = FALSE,
conf.level=0.95)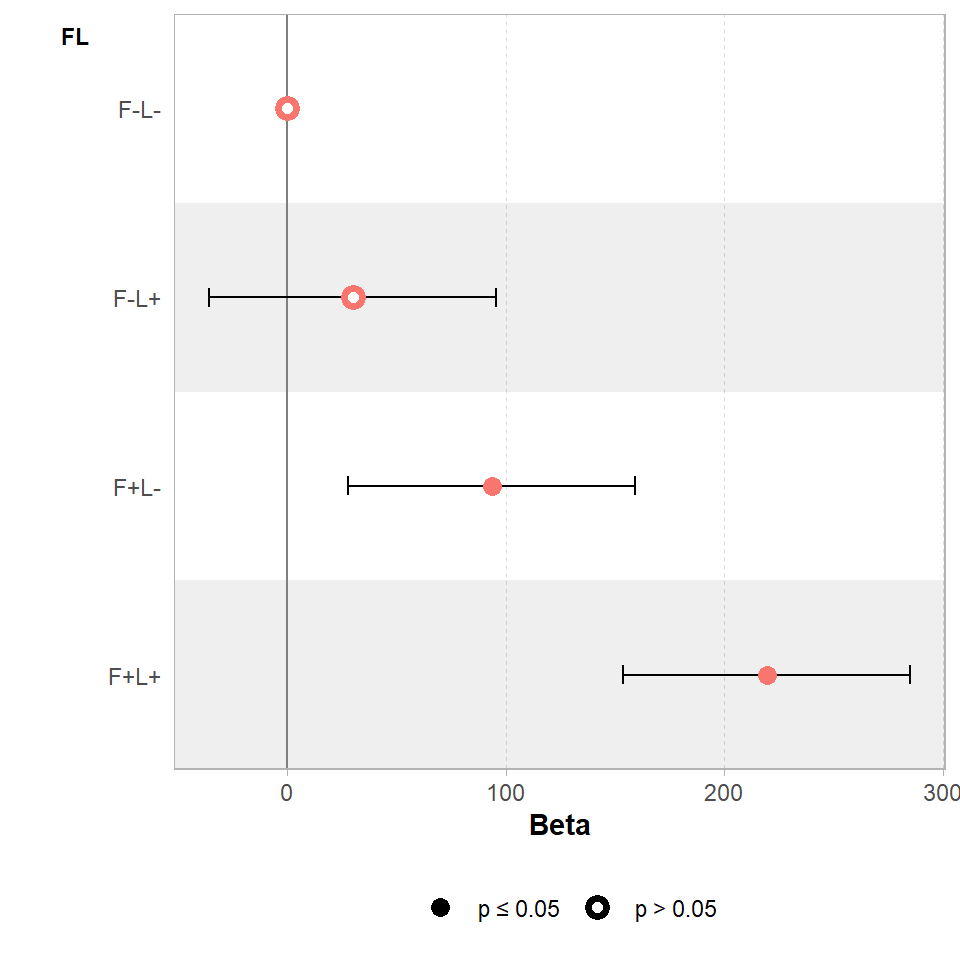
Figure 3.2: Effects of light and fertiliser treatments on biomass relative to an untreated control (error bars = 95% CI)
But what about the fourth level - combined fertiliser and light treatments? If there is no interaction (combined effect) between light and fertiliser then we would expect the average biomass difference caused by the light and the and the average biomass difference caused by fertiliser to add together to approximately the value found in the combined treatment.
In other words if one treatment has an effect size of A, and another treatment has an effect size of B, then ANOVA predicts that in combination the effect size of the combined treatments is A + B.
# combine the average mean differences of the light effect and fertiliser effect
coef(ls_1)[2] + coef(ls_1)[3]
# compare this to the average difference of the combined treatment
coef(ls_1)[4]## FLF-L+
## 123.8187
## FLF+L+
## 219.225In this example we can see clearly that combining the separate treatments does not add up to the combined value. The mean biomass of the combined treatment is well above the additive prediction.
The mean biomass of the combined treatment is well above what we would expect from the additive effects alone. This suggests there may be a positive interaction (that light and fertiliser treatments produce a sum effect that is greater than could be predicted by looking at their individual effects).
Using our one-way ANOVA design we are able to accurately estimate the mean difference between the controlled group and the combined treatment group. But we cannot really say anything concrete about the strength of the interaction effect e.g. is their a true interaction? how confident can we be in this effect? How does the strength of the interaction effect compare to the main effects?
In contrast to the one-way ANOVA approach, a factorial design lets us test and compare additive effects and interaction effects
15.4 Testing for interactions
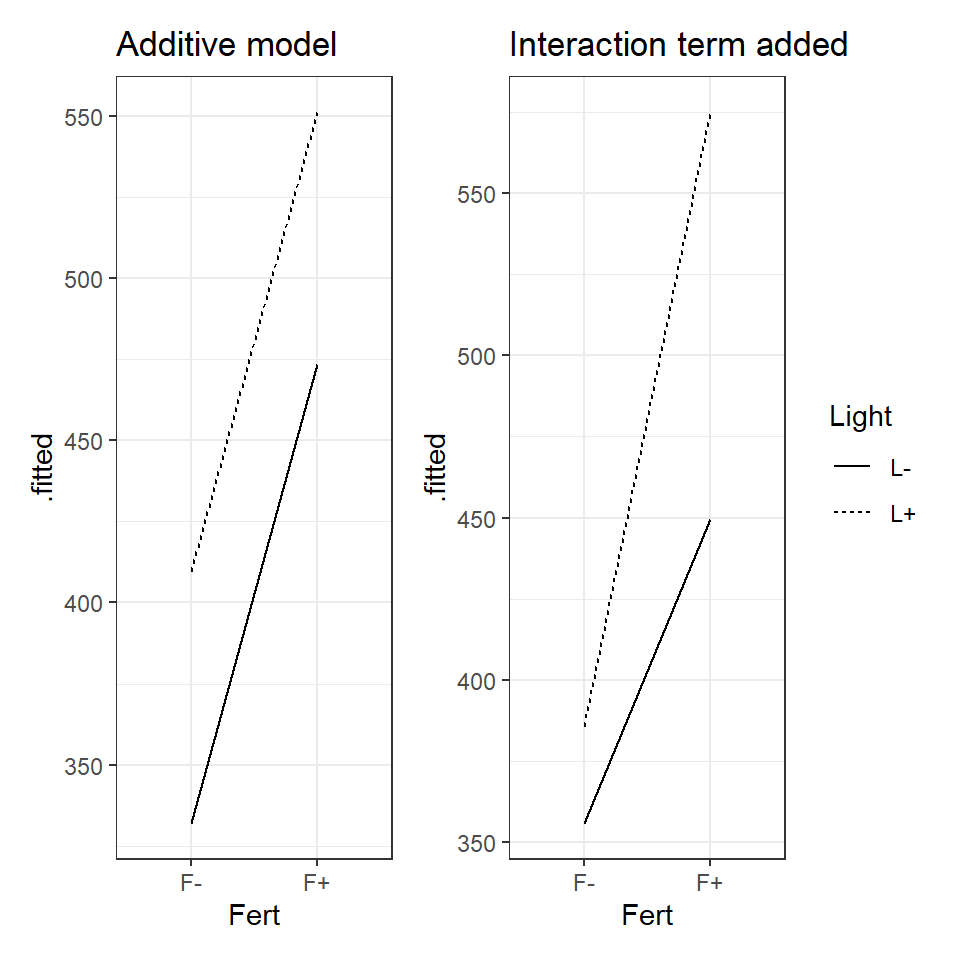
Figure 3.3: Left an illustration of an additive model, Right an illustration of a model with an interaction effect.
When the data can be best explained by an additive model, we expect new terms to shift the intercept up or down but the slope of the line to remain the same. An interaction effect changes the relationship as such we should see different gradients.
Look at the figure and determine whether you think there is evidence for an interaction effect?
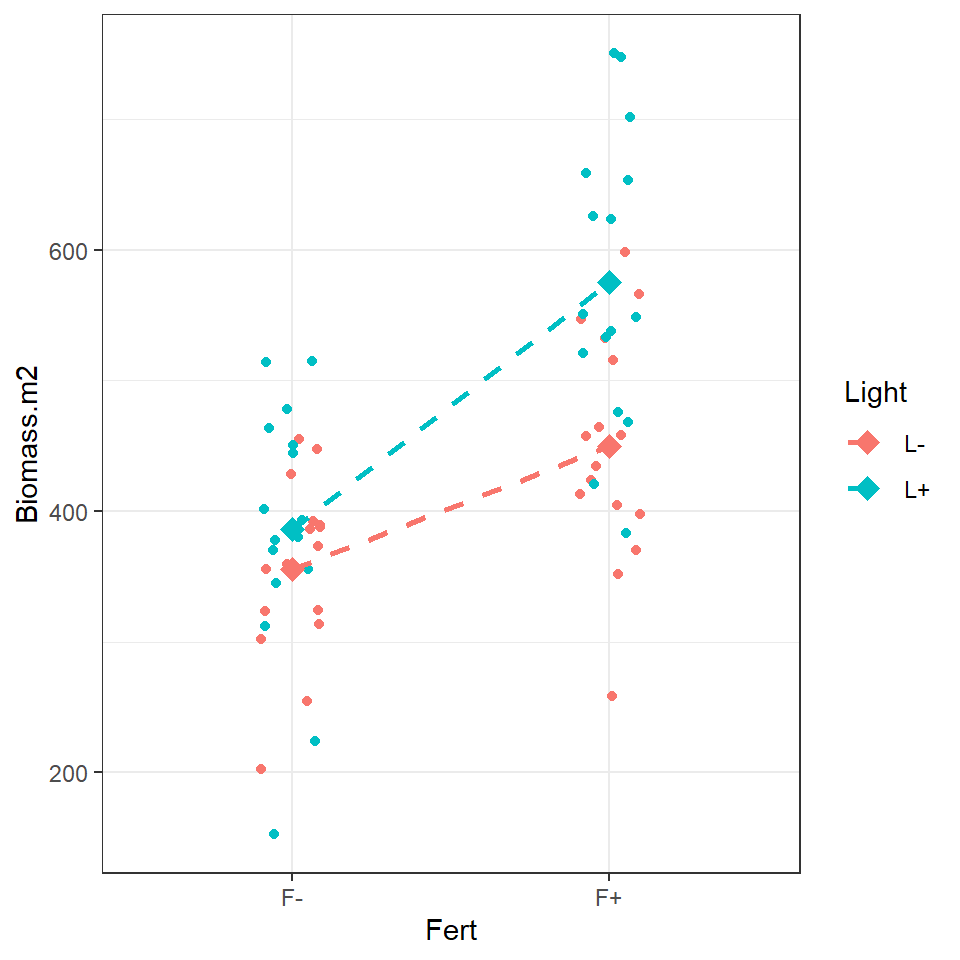
biomass %>% ggplot(aes(x=Fert, y=Biomass.m2, colour = Light, fill = Light, group = Light))+
geom_jitter(width=0.1) +
stat_summary(
geom = "point",
fun = "mean",
size = 3,
shape = 23
)+stat_summary(
geom = "line",
fun = "mean",
size = 1, linetype = "dashed"
)
To produce an interactive model, we need to use the separate factors for fertiliser and light rather than the single fl factor. When we make this model, we include the main effects of Light and Fert, if the additive model explains sufficient variance then this will be enough, but if we suspect an interaction term we add this as Light:Fert written out as follows:
ls_2 <- lm(Biomass.m2 ~ Fert + # main effect
Light + # main effect
Fert:Light, # interaction term
data = biomass)
summary(ls_2)##
## Call:
## lm(formula = Biomass.m2 ~ Fert + Light + Fert:Light, data = biomass)
##
## Residuals:
## Min 1Q Median 3Q Max
## -233.619 -42.842 1.356 67.961 175.381
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 355.79 23.14 15.376 < 2e-16 ***
## FertF+ 93.69 32.72 2.863 0.00577 **
## LightL+ 30.13 32.72 0.921 0.36095
## FertF+:LightL+ 95.41 46.28 2.062 0.04359 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 92.56 on 60 degrees of freedom
## Multiple R-squared: 0.4686, Adjusted R-squared: 0.442
## F-statistic: 17.63 on 3 and 60 DF, p-value: 2.528e-08Notice the estimates of the mean differences are the same as the previous one-way ANOVA model. The fourth line now indicates how much of an effect the two factors interacting changes the mean. Also note the standard error is larger, there is less power to accurately estimate an interaction over a main effect.
GGally::ggcoef_model(ls_2,
show_p_values=FALSE,
signif_stars = FALSE,
conf.level=0.95)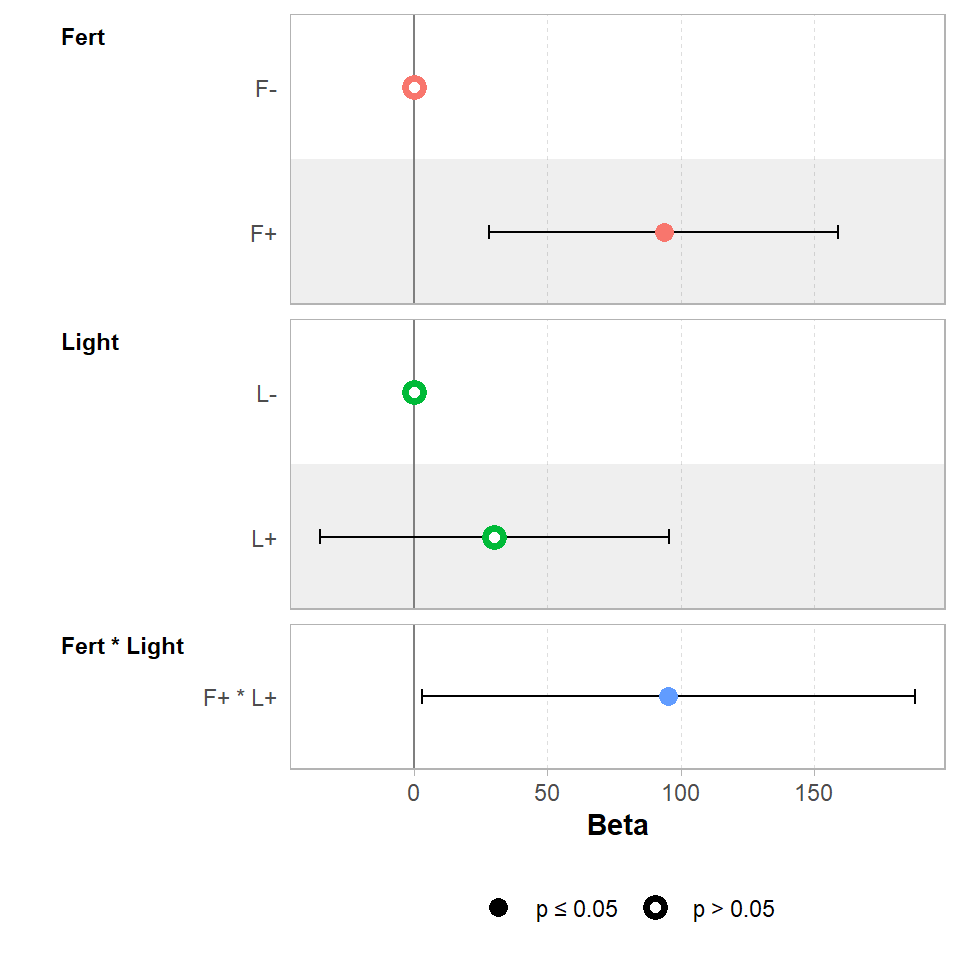
When we use a factorial combination, the last line of the table of coefficients estimates the size of the interaction effect at around 95g. So if combining the light and fertilisation treatments produced a biomass equivalent to their additive predictions, the estimate of the interaction would be zero. Instead it is 95g more than we would expect from the additive effects alone. This means in order to work out the estimated biomass for the treatment of light and fertiliser we must sum the additive effects of Light+ Fert and the interaction effect Light:Fert.
15.4.1 Model estimates and confidence intervals
When we compare this to our one-way ANOVA model, we must add the single terms and the interaction term, this should add up to the combined treatment from our first model:
## FLF+L+
## 219.225
## FertF+
## 219.225Don't make the mistake of looking at the main effect of light treatment, and reporting there is no effect because the uncertainty intervals cross zero. The main effect of light gives the average effect across the two fertiliser treatments. However, because of the interaction effect, we know this doesn't tell the whole story - whether light has an effect depends on whether fertiliser has been applied.
So, if you have a significant interaction term, you must consider the main effects, regardless of whether they are significant on their own.
15.5 ANOVA tables
So you have made a linear model with an interaction term, how do you report whether this interaction is significant? How do you report the main effect terms when there is an interaction present?
- Start with the interaction
In previous chapters we ran the anova() function directly on our linear model. This works well for simple & 'balanced' designs (there are equal sample sizes in each level of a factor), but can be misleading with 'unbalanced' designs or models with complex interactions.
In order to report an F statistic for the interaction effect, we need to carry out an F-test of two models, one with and one without the interaction effect. This is easy with the function drop1()
drop1(ls_2, test = "F")| Df | Sum of Sq | RSS | AIC | F value | Pr(>F) | |
|---|---|---|---|---|---|---|
| <none> | NA | NA | 513997.7 | 583.4298 | NA | NA |
| Fert:Light | 1 | 36409.41 | 550407.1 | 585.8099 | 4.250144 | 0.0435871 |
This F-test is testing the null hypothesis that there is no true interaction effect. The significance test rejects the null hypothesis (just). The drop1() function also provides the Akaike information criterion (AIC), an alternative method of model selection (more on this later).
We could now write this up as follows:
There was an interactive effect of light and fertiliser treatments (ANOVA F1,60 = 4.25, P = 0.044) in which combining treatments produced substantially more biomass (95.4g [95% CI: 2.8 - 188]) than expected from the additive effects alone (Fertiliser 93.7g [28.2 - 159.2], Light 30.1g [-35.3 - 95.6]).
Do not make the mistake of just reporting the statistics, the interesting bit is the size of the effect (estimate) and the uncertainty (confidence intervals).
Remember to check the assumptions of your full model
- Main effects
A good thing about the drop1() function is that if there are interactions in the model, it stops there. This is because if the interaction effect is significant, then the main effects must be included, even if they aren't significant on their own. We can make further models to test the main effects but these are less important because we already know the interaction term provides the main result.
If we decide to include reports of the main effect then estimates and confidence intervals should come from the full model, but we need to produce an interaction free model to produce accurate F-values (especially for unbalanced designs, see below).
# we have to remove the interaction term before we can keep using drop1()
ls_3 <- lm(Biomass.m2 ~ Fert + Light, data = biomass)
drop1(ls_3, test = "F")| Df | Sum of Sq | RSS | AIC | F value | Pr(>F) | |
|---|---|---|---|---|---|---|
| <none> | NA | NA | 550407.1 | 585.8099 | NA | NA |
| Fert | 1 | 319889.22 | 870296.4 | 613.1332 | 35.45238 | 0.0000001 |
| Light | 1 | 96915.47 | 647322.6 | 594.1899 | 10.74086 | 0.0017322 |
You can use this reduced model to get F values, BUT reports of estimates should come from the full model.
15.6 Balanced/Unbalanced designs
In an unbalanced design when you run the anova() function on your model, the order in which your variables were included can have an effect e.g.
lm(Fert + Light) would give a different anova table to
lm(Light + Fert)
In the examples above, you are unlikely to find much of a difference between running the drop1() function or anova() on the complex or reduced models. This is because these designs are 'balanced' (equal numbers in each level of a predictor). When designs are not balanced then the order matters when we use anova() - this is because the sum of squares is calculated sequentially (in the order of the formula), and so we could get different results depending on the order in which we assemble predictors into our model!
15.6.1 Practice
Let's start by making a deliberately unbalanced dataset
# make three vectors and combine them into a new tibble
height <- c(50,57,91,94,102,110,57,71,85,105,120)
size <- c(rep("small", 2), rep("large", 4), rep("small", 3), rep("large", 2))
treatment <- c(rep("Control", 6), rep("Removal", 5))
unbalanced <- tibble(height, size, treatment)
unbalanced| height | size | treatment |
|---|---|---|
| 50 | small | Control |
| 57 | small | Control |
| 91 | large | Control |
| 94 | large | Control |
| 102 | large | Control |
| 110 | large | Control |
| 57 | small | Removal |
| 71 | small | Removal |
| 85 | small | Removal |
| 105 | large | Removal |
| 120 | large | Removal |
15.7 Activity 1: Sums of Squares
15.8 post-hoc
In this example it is unnecessary to spend time looking at pairwise comparisons between the four possible levels, the interesting finding is to report the strength of the interaction effect. But it is possible to generate estimated means, and produce pairwise comparisons with the emmeans() package
emmeans::emmeans(ls_2, specs = pairwise ~ Light + Fert + Light:Fert) %>%
confint()
# including the argument pairwise in front of the ~ prompts the post-hoc pairwise comparisons.
# $emmeans contains the estimate mean values for each possible combination (with confidence intervals)
# $ contrasts contains tukey test post hoc comparisons between levels## $emmeans
## Light Fert emmean SE df lower.CL upper.CL
## L- F- 356 23.1 60 310 402
## L+ F- 386 23.1 60 340 432
## L- F+ 449 23.1 60 403 496
## L+ F+ 575 23.1 60 529 621
##
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df lower.CL upper.CL
## (L- F-) - (L+ F-) -30.1 32.7 60 -117 56.35
## (L- F-) - (L- F+) -93.7 32.7 60 -180 -7.22
## (L- F-) - (L+ F+) -219.2 32.7 60 -306 -132.75
## (L+ F-) - (L- F+) -63.6 32.7 60 -150 22.90
## (L+ F-) - (L+ F+) -189.1 32.7 60 -276 -102.63
## (L- F+) - (L+ F+) -125.5 32.7 60 -212 -39.06
##
## Confidence level used: 0.95
## Conf-level adjustment: tukey method for comparing a family of 4 estimates15.9 Continuous Linear Models
The previous section looked at an interaction between two categorical variables, we can also examine interactions between a factor and a continuous variable. Often referred to as ANCOVA.
pollution <- read_csv(here::here("book", "files", "pollution.csv"))The data is from an experimental study of the effects of low-level atmospheric pollutants and drought on agricultural yields. The experiment aimed to see how the yields soya bean (William variety), were affected by stress and Ozone levels. Your task is to first determine whether there is any evidence of an interaction effect, and if not report the effects of the two predictors separately.
15.10 Activity 2: Build your own analysis
Try and make as much progress as you can without checking the solutions. Click on the boxes when you need help/to check your working
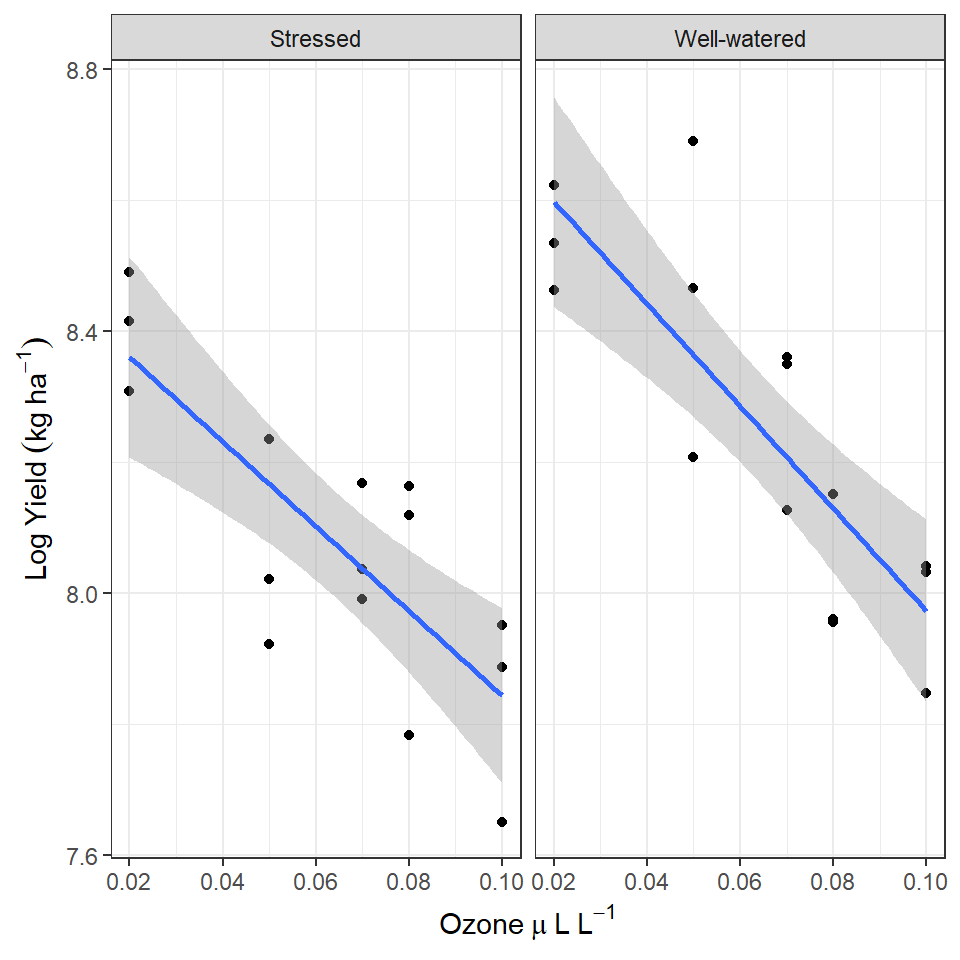
15.10.1 Check the model fit
performance::check_model(William_ls1)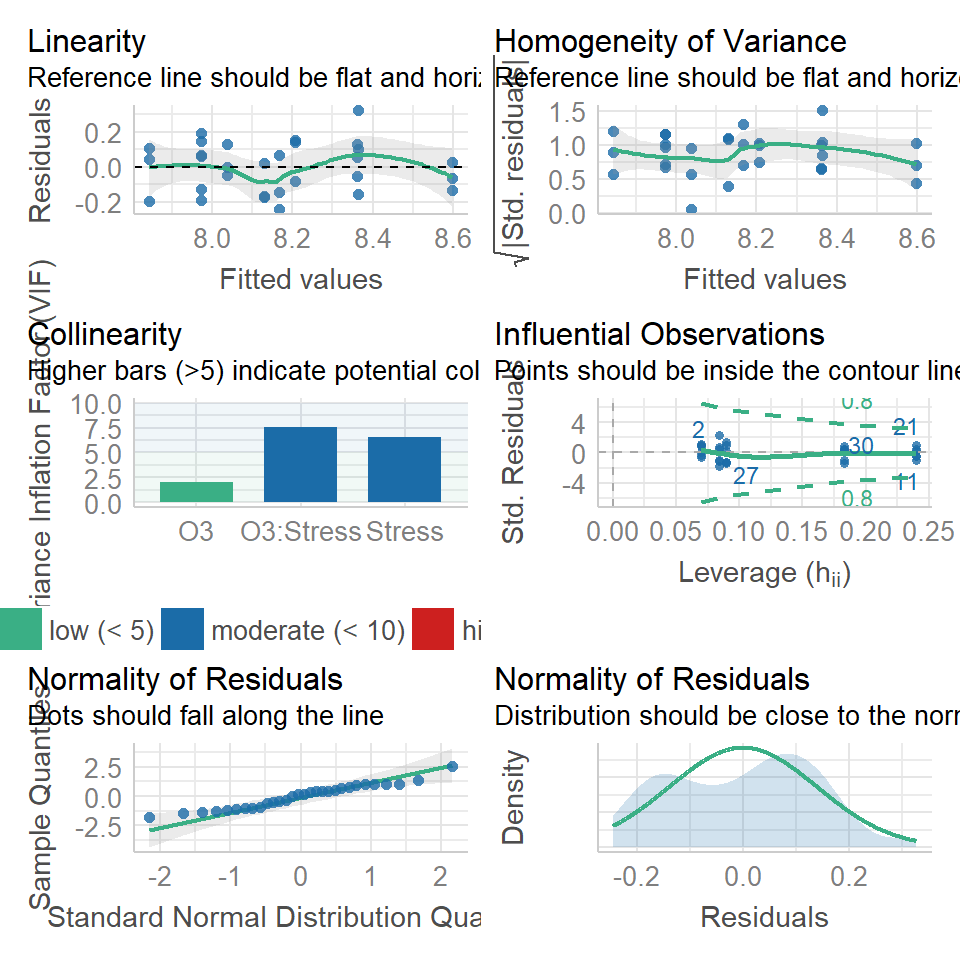
Everything looks pretty good, so now we could go ahead and simplify our model.
drop1(William_ls1, test = "F")| Df | Sum of Sq | RSS | AIC | F value | Pr(>F) | |
|---|---|---|---|---|---|---|
| <none> | NA | NA | 0.5698523 | -110.9073 | NA | NA |
| O3:Stress | 1 | 0.0101286 | 0.5799809 | -112.3787 | 0.4621281 | 0.5026393 |
William_ls2 <- lm(William ~ O3 + Stress, data = pollution)
drop1(William_ls2, test = "F")| Df | Sum of Sq | RSS | AIC | F value | Pr(>F) | |
|---|---|---|---|---|---|---|
| <none> | NA | NA | 0.5799809 | -112.37872 | NA | NA |
| O3 | 1 | 1.1381194 | 1.7181003 | -81.79934 | 52.98317 | 0.0000001 |
| Stress | 1 | 0.2376424 | 0.8176233 | -104.07653 | 11.06303 | 0.0025466 |
15.11 Summary
Always have a good hypothesis for including an interaction
When models have significant interaction effects you must always consider the main terms even if they are not significant by themselves
Report F values from interactions as a priority
IF interactions are significant then estimates should come from the full model, while F-values should come from a reduced model (for main effects). IF interaction terms are not significant they can be removed (model simplification).
Use
drop1()to avoid mistakes when using an unbalanced experiment designAlways report estimates and effect sizes - this is the important bit - and easy to lose sight of when models get more complicated